
こんにちは。 DSOC R&D グループの高橋寛治です。
最近は、R&DのD側に興味が寄っており、本連載では pytest や WebAPI化といった話が多くなってきました。
さて、つい先日に Amazon Web Services(AWS) が提供するマネージド型の機械学習サービスの一部機能を使って、機械学習を用いた任意のコンテナを推論エンドポイントとしてデプロイしました。
SageMakerのお作法さえ理解すれば便利なものだと感じたため、SageMakerの概略および任意のコンテナのデプロイ方法について紹介します。
AWS SageMakerとは
AWS SageMaker は機械学習に特化したマネージド型のクラウドコンピューティングサービスです。 機械学習に特化したという点が大きな特徴で、機械学習モデルの構築からデプロイまで AWS が提供するシステム上で行うことができます。 いくつか機能を抜粋して紹介します。
機械学習モデル構築のためのコードを書く環境として、 Jupyter Notebook 環境を提供しています。 AWS コンソール上から、「Create notebook instace」ボタンを押下して名前やインスタンスタイプを指定することで、すぐに Jupyter Notebook 環境が起動します。 SSHの設定が必要なく、ブラウザ上のリンクから Jupyter Notebook に遷移するため、環境構築の手間がほとんどありません。
トレーニングでは、コードを書いているJupyter Notebook 環境とは別のインスタンスで学習を行うことができます。 こうすることでデータの調査や簡単な前処理、モデル設計を小さなインスタンスでコストを抑えて行い、学習は別の大きなインスタンスで行えます。 もちろん起動している Jupyter Notebook上でも大きめのインスタンスを選び、学習することは可能です。
また、SageMakerは強力なデプロイ機能を提供しています。 AWS SDK経由でデプロイしたり、モデルとコンテナを指定してデプロイしたりできます。 AWS SDKから簡単にアクセス可能なエンドポイントとしてデプロイされます。 実際にURLでアクセスできるリソースとする場合には、API GatewayからAWS Lambdaへ、AWS LambdaからSageMakerのエンドポイントにアクセスという風に組み合わせることができます。
推論エンドポイントに任意のコンテナをデプロイする
今回は、Jupyter Notebook環境とデプロイ機能(推論エンドポイント)を用いて、任意のコンテナをデプロイします。 トレーニング機能は用いず、モデルは自分で構築済みのものを利用します。 リクエストに対して機械学習モデルが推論した結果を返すコンテナをデプロイするということです。
全体像
全体像を次の図に示します。
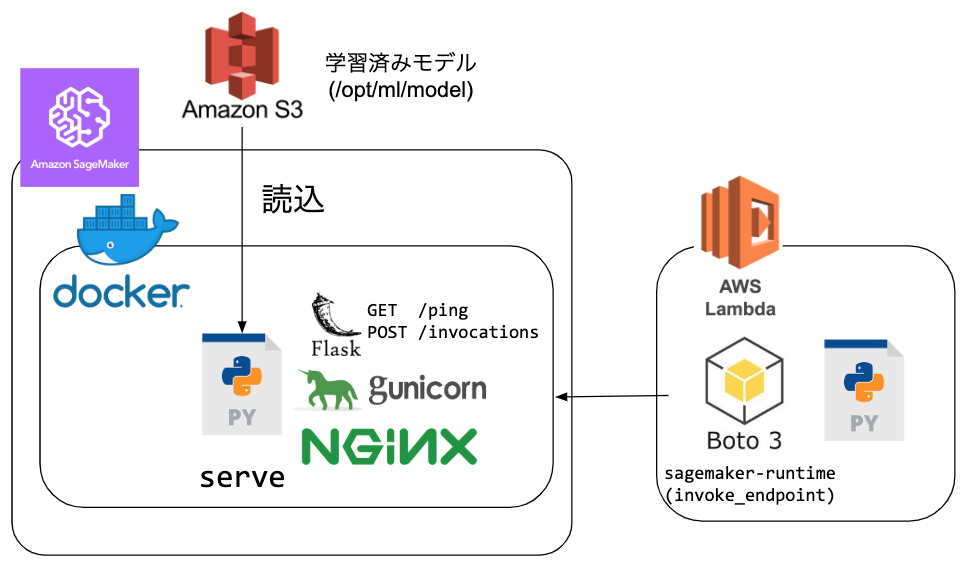
学習済みのモデルはS3バケットに配置します。
tar.gz アーカイブに必要なファイルを追加します。
これはコンテナの /opt/ml/model 以下に展開されます。
任意のコンテナは、8080ポートで ping もしくは invocations リソースを受け付けるものを作成します。
コンテナ起動時にCMDにserveが指定され、serveがコンテナの設定を行います。
AWSのサンプルで利用されているNginxとgunicornの組み合わせを図示しています。
ping はヘルスチェック用のエンドポイントで、ステータスコード200を返すと正常とSageMakerから認識されます。
invocations エンドポイントは推論するデータを受け取るものです。
受け取って処理したものを返します。
推論エンドポイントは、PythonであればAWS SDK boto3の sagemaker-runtime クライアントの invoke_endpoint メソッドから呼び出すことが可能です。
まとめると、推論用のコンテナの動作の概要はおおまかに次のようになります。
- CMDに
serveが指定されたコンテナが起動する- コンテナ起動時に指定したS3の
tar.gzアーカイブを/opt/ml/modelに展開する
- コンテナ起動時に指定したS3の
serveスクリプトがエンドポイントを起動する- Nginxを起動する
- gunicornを起動する
- Flaskで書かれたWSGIアプリが起動する
- リクエストを待ち受ける
コードの具体的な説明
Amazon Web Services Labsが公開しているコードをもとに説明します。amazon-sagemaker-examplesに含まれるBring-your-own Algorithm Sampleです。
推論エンドポイントの作成には、Dockerfile と decision_trees ディレクトリ以下の nginx.cong, predictor.py, serve, wsgi.py を利用します。
Dockerfile
推論エンドポイントとしてデプロイするコンテナです。 ubuntu 16.04をベースとしたイメージで、PythonやNginxをセットアップします。
nginx.conf
コンテナで起動させるNginxの設定ファイルです。
8080番ポートで /ping もしくは /invocations にアクセスがあった場合に、Unixソケット(gunicorn)に転送します。
wsgi.py
gunicornが起動するWSGIアプリです。
predictor.py の myapp を wsgi:app という名前空間に変更しています。
serve
Nginxおよびgunicornを起動するPythonスクリプトで、Dockerが実行する命令です。
拡張子はついていないですが、shebangでpythonが指定されているため、Pythonコードとして実行されます。
predictor.py
Flaskで書かれたWebAPIです。
リクエストに応じて機械学習モデルにより推論を行います。
ポイントはクラスメソッドでモデルの読み込みや推論を行う ScoringService です。
クラス変数としてモデルを読み込んでいます。
これはシングルトンとして振る舞います。
インスタンスを作ること無く、モデルの読み込みや推論を行います。
これらをベースに改造していくことで、任意の機械学習モデルを容易に持ち込むことができます。
任意のモデルを利用する場合には、特に predictor.py を書き換えることとなります。
たとえば、複数モデルを読み込む場合には、get_model で読み込むモデルを増やします。
モデルが想定する入力となっていない場合は、predictメソッドやtransformation関数に前処理を加えます。
デプロイ
Dockerfile をビルドし、Amazon Elastic Container Registry(ECR)にプッシュします。
また、モデルファイルは任意のS3バケットに配置します。
Dockerイメージのプッシュおよびモデルファイルの配置が終わったら、Amazon SageMakerコンソールの「推論」>「モデル」の「モデルの作成」を押下します。
次のような画面が出てくるため、項目を埋めていきます。
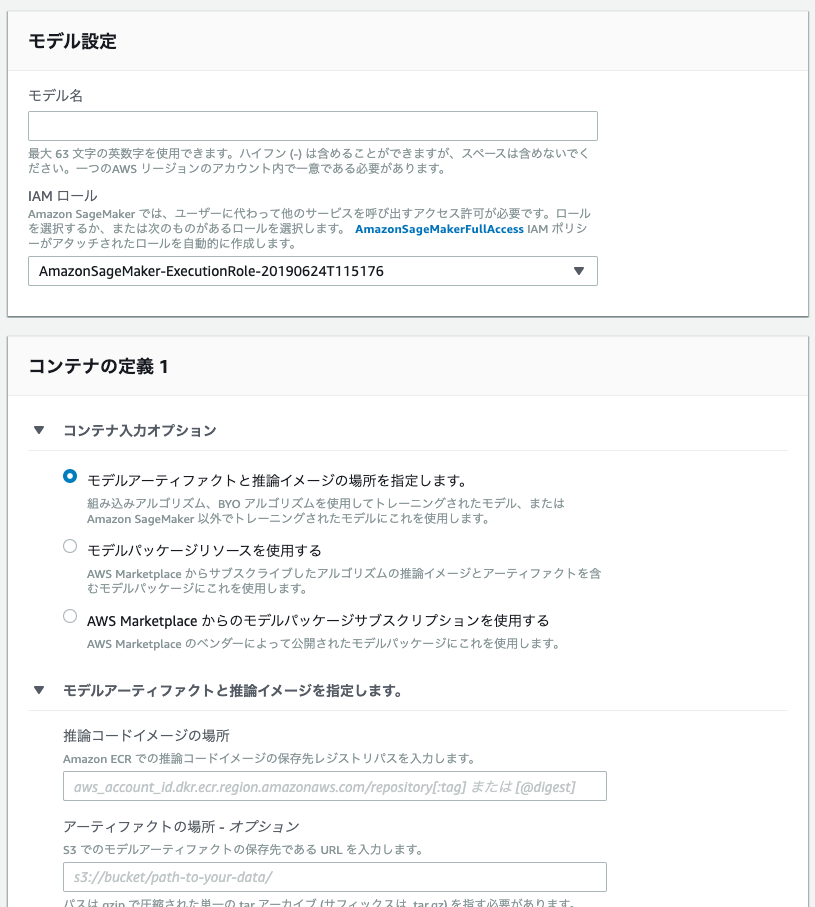
プッシュしたコンテナは、「推論コードイメージの場所」で指定します(例 0000000000.dkr.ecr.region.amazonaws.com/hogehoge:latest)。
モデルファイルは、「アーティファクトの場所 - オプション」を指定します(例 s3://hogehoge/fuga/artifacts.tar.gz)。
モデルの作成を完了すれば、あとはエンドポイントの作成をするのみです。 作成したモデルを選択し、「エンドポイントの作成」から作成します。
作ったエンドポイントの動作確認は、ノートブックインスタンスから boto3 の sagemaker-runtime クライアントでリクエストを送ることができます。
import json import boto3 # SageMakerクライアントを作成 sagemaker_runtime = boto3.client("sagemaker-runtime") # 推論エンドポイントにリクエスト response = sagemaker_runtime.invoke_endpoint( EndpointName="エンドポイントの名前", Body=json.dumps(送るデータ), ContentType="application/json", Accept="application/json" ) # 結果を表示 print(response["Body"].read().decode())
業務での実例
入力文書に対して、ある文書群から文書埋め込み(Sentence Embedding)との類似度を算出して、最も類似度の高い文書のIDを返すという簡単なエンドポイントを作成しました。 入力は文書(文字列)で、比較対象は文書埋め込みとなるため、入力を比較対象の埋め込みと同様の手法でベクトル化する処理を記述します。 また、ベクトル化前に形態素解析が必要ですので、形態素解析の設定も必要です。
モデルアーカイブ xxx.tar.gzは、次のファイルを含んでいます。
- ある文書群の文書埋め込み
- 形態素解析辞書
- 入力文書を文書埋め込みに変換するために必要なモデル
tar -cvf artifacts.tar.gz artifacts のように artifacts 以下に利用するモデルファイルを配置して、アーカイブを作成します。
作成したアーカイブをS3の所定のバケットに配置します。
ただしモデルのサイズが大きく、起動時の読み込みに時間を要します。
サンプルコードの ping メソッドでは、モデルが読み込めれば 200 を返しています。
ヘルスチェックがタイムアウトしてしまうため、この例ではモデルの読み込みにかかわらずエンドポイントが稼働していれば200を返すように変更しています。
トレーニングは利用しませんでしたが、デプロイ方法の一つとして推論エンドポイントを使ってみたところ、コンテナとモデルを配置するだけでエンドポイントを起動できるため便利そうな印象です。
マネージドサービスをうまく使う
SageMakerは学習データの作成からリリースまでを補助する高機能なサービスです。 新しい仕組みがゆえに覚えることが多かったり、気をつけなければいけない点が異なります。 SageMakerは幸いにもDockerコンテナベースでデプロイできるため、万が一SageMakerがシステム組み込み上あわなかったとしても、切り替えられるでしょう。
マネージドサービスは積極的に試してみて、よりよいものを取り込んでいきたいところです。
執筆者プロフィール
高橋寛治 Sansan株式会社 DSOC (Data Strategy & Operation Center) R&Dグループ研究員
阿南工業高等専門学校卒業後に、長岡技術科学大学に編入学。同大学大学院電気電子情報工学専攻修了。在学中は、自然言語処理の研究に取り組み、解析ツールの開発や機械翻訳に関連する研究を行う。大学院を卒業後、2017年にSansan株式会社に入社。キーワード抽出など自然言語処理を生かした研究に取り組む。