こんにちは、Strategic Products Engineering Unit SRE Groupの辻田です。 2025年4月にラスベガスで開催されたGoogle Cloud Next 25にて、Firebase Genkitに関するWorkshopに参加してきました。
Firebase Genkitは、プロダクション対応のAIアプリケーションを構築するためのオープンソースのフレームワークです。Genkitを使うことで、生成AIアプリケーションの開発がより簡単かつ柔軟にできるようになります。
本記事では、Genkitの概要から、RAG(Retrieval-Augmented Generation)を活用した実装例までを紹介します。
Google Cloud Next 25関連の記事はこちらです。
【Google Cloud Next 25】ラスベガス出張のパッキングと参加予定セッション - Sansan Tech Blog
【Google Cloud Next 25】GKE編 - Sansan Tech Blog
Firebase Genkitとは?
Genkitは、AIを活用した機能開発を効率化するために設計されたツールキットです。チャットボット、インテリジェントエージェント、ワークフローの自動化、おすすめシステムなど、幅広いアプリケーションへのAI導入をサポートします。
Genkitで実現できること:
- テキストと画像の生成: 生成AIモデルを活用したコンテンツ生成が可能です。
- 型安全な構造化データの生成: 構造化されたデータをAIに生成させることで、アプリケーションでの扱いが容易になります。
- ツールの呼び出し: AIから外部ツールやAPIを呼び出すワークフローを構築できます。
- プロンプトテンプレート: 効果的なプロンプト管理と再利用を支援します。
- 永続化されたチャットインターフェース: ユーザーとの対話履歴を保持するチャット機能を実装できます。
- AIワークフロー: 複数のAIモデルやツールを組み合わせた複雑なワークフローを定義・実行できます。
- AIによるデータ取得(RAG): 外部データソースから関連情報を取得し、LLMの応答精度を向上させるRAG(検索拡張生成)を実装できます。
GenkitはさまざまなLLMをサポートしており、Google Gemini、Google Imagen、OpenAI、Anthropic、Llama、Mistral AI、Ollamaなど、目的に合わせたモデルを選択して利用できます。
RAGの実装例
Genkitを使えば、RAGの導入も容易に行えます。RAGは、検索技術と生成AIを組み合わせることで、モデルが学習データにない最新の情報や特定のドキュメントの内容に基づいた、よりコンテキストに関連性の高い正確な応答を生成することを可能にします。
以下に、公式 Codelab を参考にしたRAGの実装例を紹介します。
ユーザーが旅行先を選び、旅行先のアクティビティを選択し、旅行プランを作成できるアプリケーションを想定しています。
Genkitを使用して、ユーザーが提供するインスピレーションに基づいて目的地を提案する機能を実装します。生成モデルのプロバイダとして Genkit と Google Cloud の Vertex AI(Gemini)を使用します。
1. Genkit Developer UIを起動
Codelabの手順に従って、開発環境とFirebaseプロジェクトをセットアップします。
Genkitには、生成AIの開発を効率化するための専用Developer UIが用意されています。次のコマンドを実行して、Genkit Developer UI を起動します。
npm run dev:genkit
すると、このようなUIが立ち上がります。

生成モデルの出力を調整するために、次のようなパラメータを指定できます。
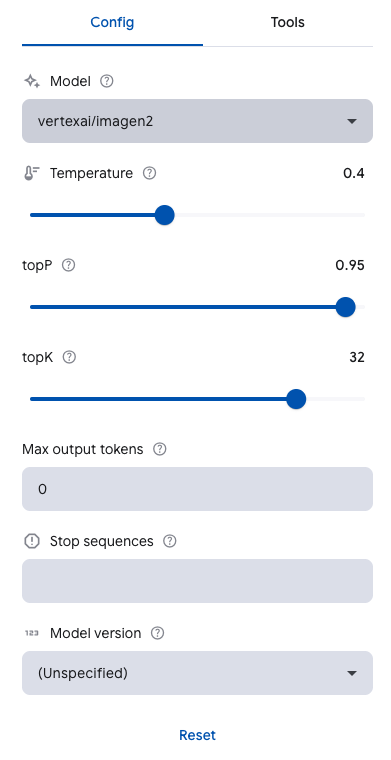
Temperature: 出力のランダムさを制御します。値を低くすると予測可能で正確な回答が得られやすくなり、値を高くすると多様で創造的な結果になります。
topP(トークンの確率分布): 次に選ばれる単語の候補をどれだけ広く考慮するかを決めます。値が高いほど、あまり確率の高くない単語も含めて多様な応答が生成されやすくなります。
topK(最大候補数): トークン選択時に考慮する単語数の上限を設定します。たとえば topK = 40 とすれば、確率が高い上位40語から選ばれます。
他にも、次のような機能を活用しながらプロンプトの設計や出力の検証を直感的に行うことができます。
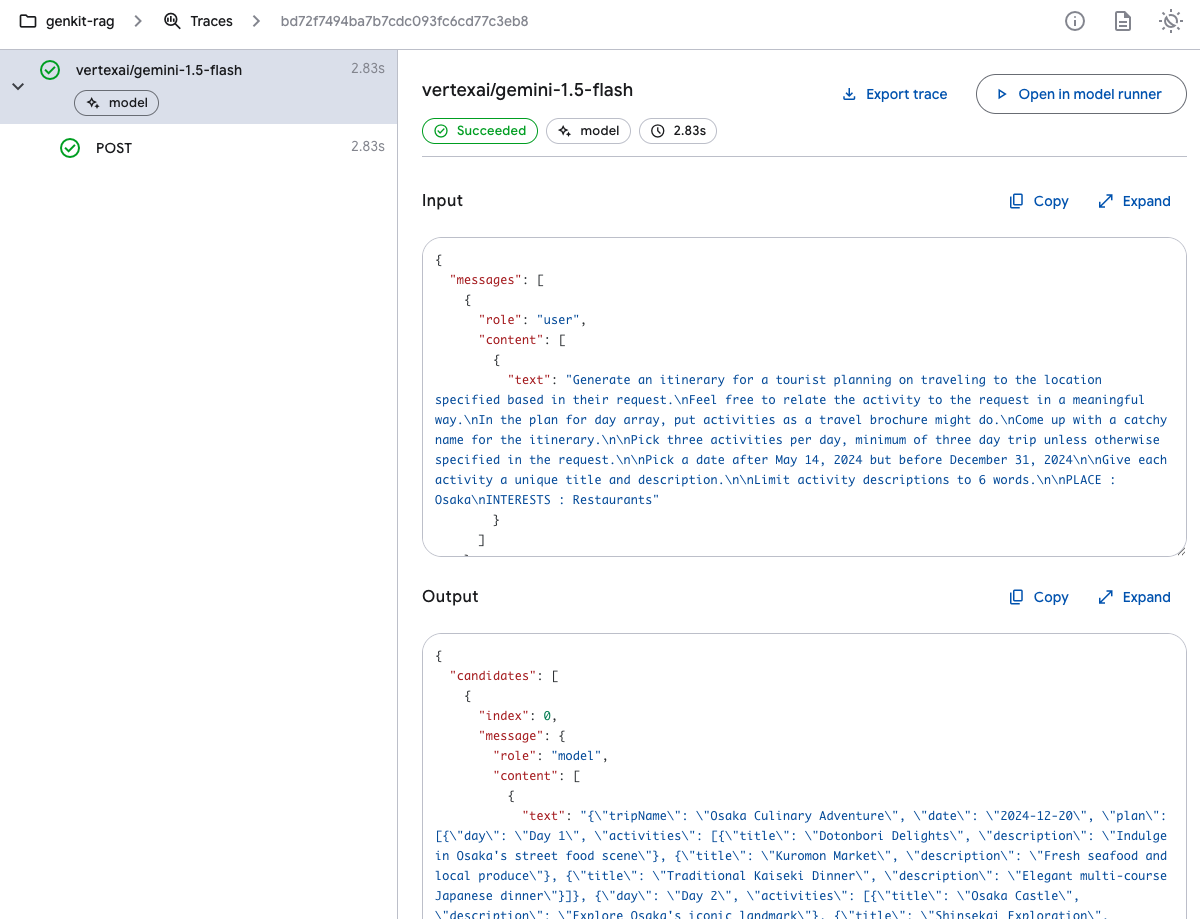
フローの実行状態をトレースとして保存
Genkitでは、複数の処理をつなぎ合わせて一連のロジックとして定義する「フロー(flow)」という仕組みがあります。たとえば、ユーザーの入力を受け取り、検索を実行し、生成モデルで回答を生成する、といった一連の処理をひとつのフローとして記述できます。
フローは通常の関数のように TypeScriptで定義でき、テストや再利用も簡単です。これにより、生成AIの活用ロジックをモジュール化・構造化して開発できます。Genkitは、フローの実行中に発生したイベントや状態を「トレース」として記録できます。これにより、デバッグや挙動の可視化が容易になります。
Dotprompt でプロンプトを管理
Genkit では、.prompt 形式のファイル(Dotprompt)を使ってプロンプトを定義できます。これは「プロンプトをコードとして扱う」アプローチで、アプリケーションコードと一緒にバージョン管理や再利用が可能になります。
---
model: vertexai/gemini-1.5-flash
input:
schema:
language: string
---
A greating in {{language}}.
Nothing else.
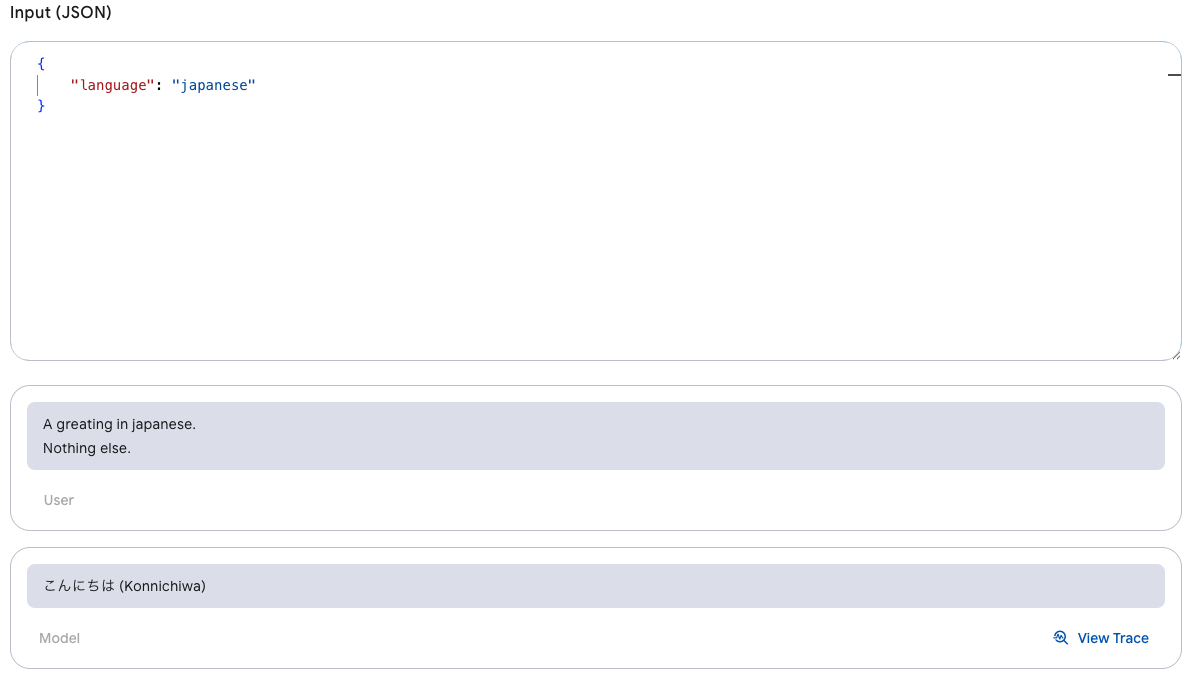
このように簡単なクエリで、省略形、スペルミス、不完全なプロンプトの調査が可能です。
出力をスキーマで構造化
単なるテキスト出力だけでなく、構造化データ(スキーマ)を生成するよう指示もできます。これにより、UI との統合やデータの扱いが格段にスムーズになります。
- 出力が スキーマに準拠しているか自動検証
- スキーマに合わない場合は 再生成や修復が可能
- UI への統合、検証、エラー処理が一気通貫で行える
{ "interests": [ "Restaurants" ], "place": "Osaka" }
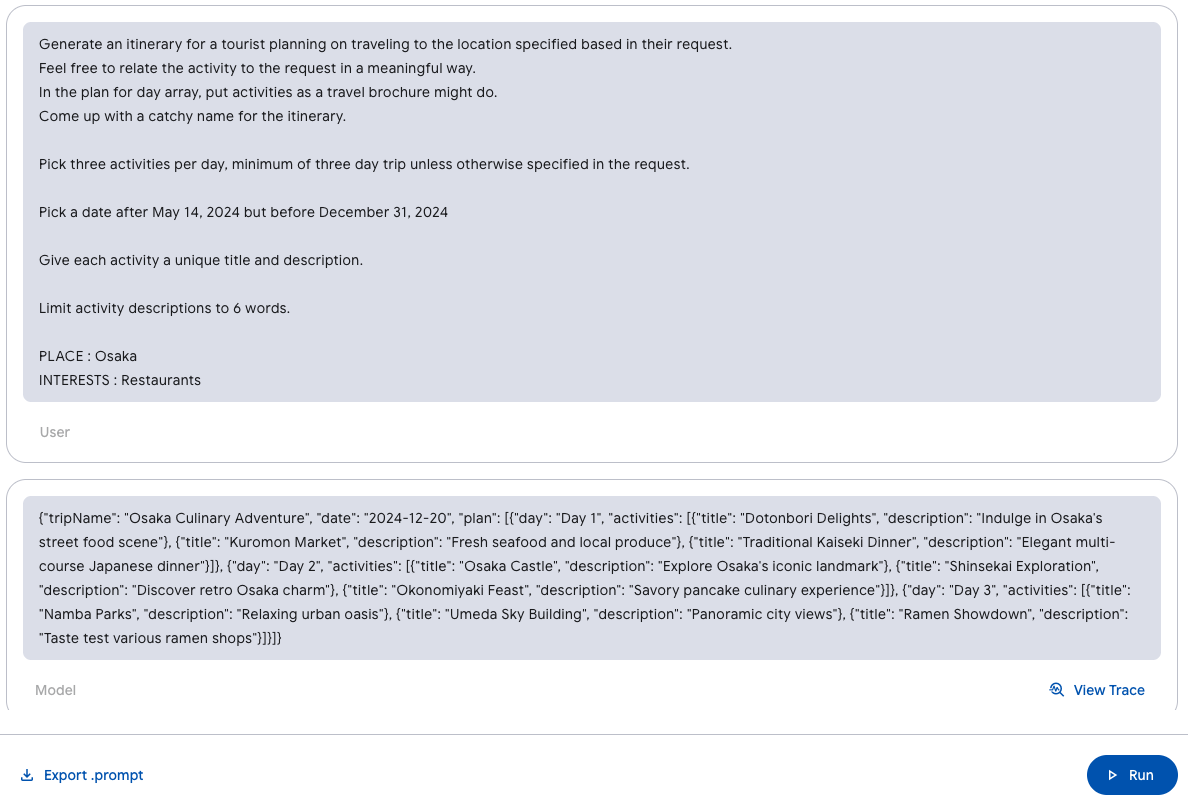
このようにGenkit Developer UIを活用すれば、プロンプトの開発・テスト・改善・統合までをワンストップで行うことができ、より高度な生成体験をアプリに取り込めます。
2. ベクトル類似度検索による取得を実装
AIモデルを活用してクリエイティブな出力を生成するだけでなく、特定のコンテキストに基づいた出力を得ることは、実用的なアプリケーション開発において非常に重要です。たとえば、目的地の提案アプリでは、候補が既存のデータベース内の情報に基づいて生成される必要があります。
ユーザーの入力(例:「パリのロマンチックなディナー」)に基づいて、Firestoreに保存された場所とアクティビティのデータベースから関連する候補を取得し、その情報をGeminiモデルに渡して回答を生成する仕組みを実装します。
このような処理では、エンベディングとベクトル類似性検索を活用するのが効果的です。
ベクトル類似性検索とは?
- エンベディング:テキストを意味的に捉えた数値ベクトルに変換する技術で、似た意味の文は類似したベクトルになります。
- ベクトル類似性検索:クエリのエンベディングとデータベース内のエンベディングを比較し、意味的に近いものを検索します。
以下のような設定で検索を実装します。
export const placesRetriever = defineFirestoreRetriever(ai, { name: 'placesRetriever', firestore, collection: 'places', contentField: 'knownFor', vectorField: 'embedding', embedder: textEmbeddingGecko003, distanceMeasure: 'COSINE', });
この定義により、placesRetrieverはユーザーの入力をエンベディング化し、意味的に近いknownForフィールドを持つFirestoreドキュメントを検索するようになります。
Retrieverとは?
Retrieverは、ユーザーからのクエリに応じて、外部データソースから関連情報を取得する役割を持つコンポーネントです。RAGアーキテクチャにおいては、Retrieverが中心的な役割を果たします。
- クエリの処理:ユーザーの自然言語による入力を受け取り、それを処理可能な形式(例:エンベディング)に変換します。
- 外部データソースとの照合:データベース、ファイル、API などから関連性の高い情報を検索・取得します。
- 生成モデルへの橋渡し:取得した情報を生成モデル(Gemini など)に渡して、より文脈に合った出力を得るために活用します。
Firestoreのベクトル検索インデックス
Firestore でベクトル検索を有効にするには、次のようなインデックスを作成します。
gcloud firestore indexes composite create \ --project=YOUR_PROJECT_ID \ --collection-group=places \ --query-scope=COLLECTION \ --field-config field-path=embedding,vector-config='{"dimension":"768","flat": "{}"}'
これにより、検索対象のベクトルフィールド(embedding)に対する類似度計算が可能になります。
この仕組みによって、ユーザーの曖昧な自然言語によるリクエストに対しても、データベースにある具体的な情報をもとに適切な候補を生成できるようになります。
3. RAGを実装
最後にいままでのコンポーネントを統合して、RAGフローを実装します。次のコードは、ユーザーからの旅行リクエストと画像を元に、関連する観光地を検索し、それぞれに合わせた旅程を生成する一連の処理を定義したものです。
export const itineraryFlow = ai.defineFlow( { name: 'itineraryFlow', inputSchema: ItineraryFlowInput, outputSchema: ItineraryFlowOutput, }, async (tripDetails) => { // imageUrlsが指定されていれば、それをimgDescriptionプロンプトに渡して説明文を生成 // これにより、ユーザーが提供した画像から文脈を補強できる const imgDescription = await run('imgDescription', async () => { if (!tripDetails.imageUrls?.length) { return ''; } const imgDescription = await ai.prompt('imgDescription'); const result = await imgDescription({ input: { imageUrls: tripDetails.imageUrls }, }); return result.text; }); // ユーザーのリクエストと画像の説明文を組み合わせて、カスタムretrieverを使って類似観光地を検索 // ai.retrieve() により、ベクトル検索が実行され、関連性の高い目的地が返される const places = await run( 'Retrieve matching places', { imgDescription, request: tripDetails.request }, async () => { const docs = await ai.retrieve({ retriever: placesRetriever, query: `${tripDetails.request}\n${imgDescription}`, options: { limit: 3, }, }); return docs.map((doc) => { const data = doc.toJSON(); const place: Place = { continent: '', country: '', imageUrl: '', knownFor: '', name: '', ref: '', tags: [], ...data.metadata, }; if (data.content[0].text) { place.knownFor = data.content[0].text; } delete place.embedding; return place; }); }, ); // 取得した観光地ごとに、旅程を個別に生成 // 各観光地の情報とリクエストをもとに、generateItinerary プロンプトが使用される const itineraries = await Promise.all( places.map((place, i) => run(`Generate itinerary #${i + 1}`, () => generateItinerary(tripDetails.request, place), ), ), ); return itineraries.filter((itinerary) => itinerary !== null); }, );
- 画像説明の生成(任意)
- 観光地の検索(Retriever を使用したベクトル検索)
- 旅程の生成(観光地ごとのプロンプト実行)
- 出力を整形して返す
このようにして、GenkitのフローとRetriever、プロンプトを連携させ、一貫性のある旅行プランを構築するRAGパイプラインが実装できました。
まとめ
AIアプリケーションをローカルで簡単に開発&トレースを活用してデバッグできるのは便利だと思いました。RAGの実装は難しいと思っていましたが、Genkitを使うことで比較的容易に実装できることがわかりました。また、Gemini以外のLLMもサポートしているので、他のモデルを使いたい場合でも柔軟に対応できるのも魅力です。
ぜひ自分たちのチームでもGenkitを活用して、AIアプリケーションの開発に挑戦してみたいと思います。Platformのポータルなどに組み込んで、よりインタラクティブでパーソナライズされた体験を提供できたら面白そうです。
最後に、Firebase Genkitは、AI機能をアプリケーションに組み込みたい開発者にとって強力なツールキットです。豊富な機能と多様なLLMのサポートにより、革新的なユーザー体験を提供できます。特にRAGの実装は、AI応答の精度と関連性を向上させる上で非常に有効であり、Genkitはその実現をサポートします。ぜひGenkitを活用して、あなたのアプリケーションにAIの力を取り入れてみてください。
おまけ
4/11に開催された音楽を楽しめるパーティ「Next at Night」の様子

